Learn Agentic AI in the most entertaining and personalised way
Multimodal AI has a hidden problem.
Reading Time: < 1 minute
Multimodal AI has a hidden problem.
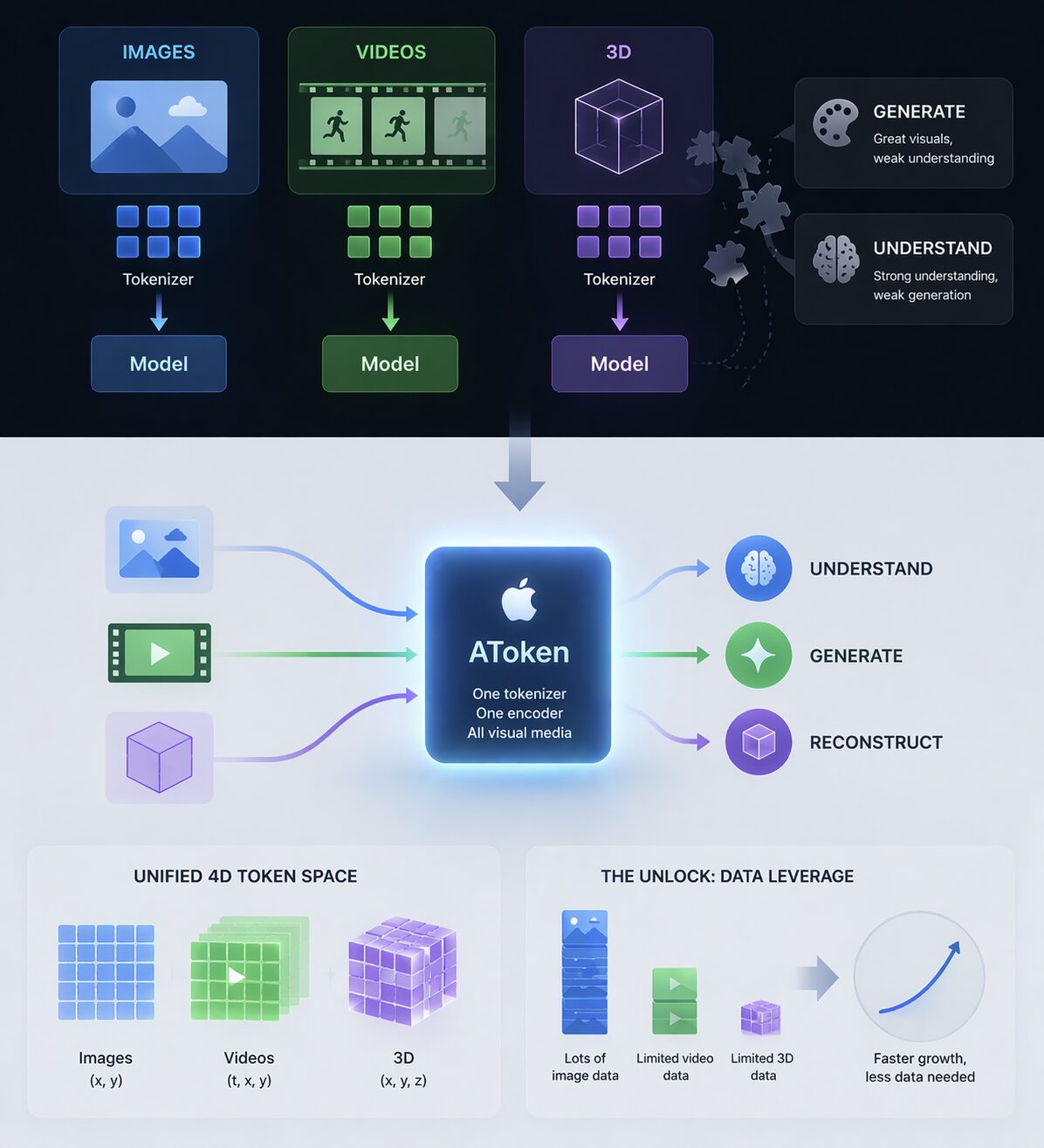
Images → one tokenizer
Videos → another
3D → completely different setup
And it gets worse:
– Models that generate visuals don’t really understand them
– Models that understand visuals can’t generate them well
So instead of one intelligent system,
we end up with a stack of disconnected capabilities.
Apple is trying to take a very different approach with new model – AToken
Instead of adding more pieces, it removes them.
– One tokenizer
– One encoder
– Works across images, videos, and 3D
The core idea:
Treat all visual data in a unified format.
Images → (x, y)
Videos → (t, x, y)
3D → (x, y, z)
Everything becomes part of a single 4D token space.
So the same model can:
– Understand
– Generate
– Reconstruct
Across all formats.
And the real unlock:
Data leverage.
We have massive image datasets.
But very limited video and 3D data.
With a shared model:
- Learning transfers across modalities
- Less data needed overall
- Faster capability growth
This is exactly what happened with LLMs.
One tokenizer → text, code, conversations, everything.
Now we’re seeing the same shift in vision.
From:
“different models for different media”
To:
one model that understands the visual world.
Learn AI Agents through entertaining web series, and not lecture-style video
Like us, if you also hate learning through lectures then we invite you to watch our engaging educational web series.
You can explore the courses here: https://www.tisdoms.com/
If you have questions, feedback, or disagree with something in this article, I’d love to hear your perspective. Connect with me on LinkedIn:
https://www.linkedin.com/in/nikhileshtayal/
Common questions about the programs are answered here:
https://www.tisdoms.com/faqs-tisdoms-an-edu-tain-tech-platform-to-learn-ai/